For this project, we used the IsamasRed dataset, a publicly available dataset that tracks Reddit discussions on the Israel-Hamas conflict from August 2023 to November 2023. This dataset was compiled by researchers Kai Chen, Zihao He, Keith Burghardt, Jingxin Zhang, and Kristina Lerman, and was published in January 2024 [https://github.com/kaichen23/israel-hamas]. It includes nearly 400,000 conversations and over 8 million comments across Reddit, capturing the public discourse surrounding this event.
The data collection process used a keyword extraction framework powered by GPT-4 to ensure coverage of relevant discussions. The dataset provides detailed attributes for submissions, comments, and conversations, such as subreddit names, authors, timestamps, scores, upvotes, controversy markers, and thematic labels like “FreePalestine&Islamophobia” or “Zionism&Antisemitism.” This structure enabled us to analyze the relationship between discussion topics, engagement patterns, and user behaviors.
The data is stored in JSON format and was last updated in January 2024. Due to its large size, we contacted the authors directly to access the full dataset, as it was too big to host on our own repository. We encountered file size issues, particularly with the comments.csv file, which we addressed by resampling the data to 500,000 rows for comments and 50,000 rows for conversations. This resampling retained the time-based proportions, ensuring that trend lines remained accurate for analysis.
We analyzed the IsamasRed dataset to identify missing values across submissions and comments. We wanted to check on the accuracy and completeness of the dataset, which would affect our findings.
Code
missing_values_submissions <- submissions %>%mutate(timestamp =as_datetime(timestamp)) %>%select(subreddit, id, author, timestamp, title, text, score, upvote_ratio, upvotes) %>%# Ensure only required attributes are selectedsummarise(across(everything(), ~sum(is.na(.)))) %>%pivot_longer(cols =everything(), names_to ="attribute", values_to ="missing_count")ggplot(missing_values_submissions, aes(x =reorder(attribute, missing_count), y = missing_count)) +geom_bar(stat ="identity", fill ="steelblue") +coord_flip() +scale_y_continuous(breaks =seq(0, max(missing_values_submissions$missing_count, na.rm =TRUE), by =50000),labels = scales::comma ) +labs(title ="Missing Values in Submissions Data",x ="Attributes",y ="Count of Missing Values" ) +theme_minimal() +theme(axis.text.x =element_text(size =10),axis.text.y =element_text(size =10),plot.title =element_text(size =14, face ="bold"),axis.title =element_text(size =12) )
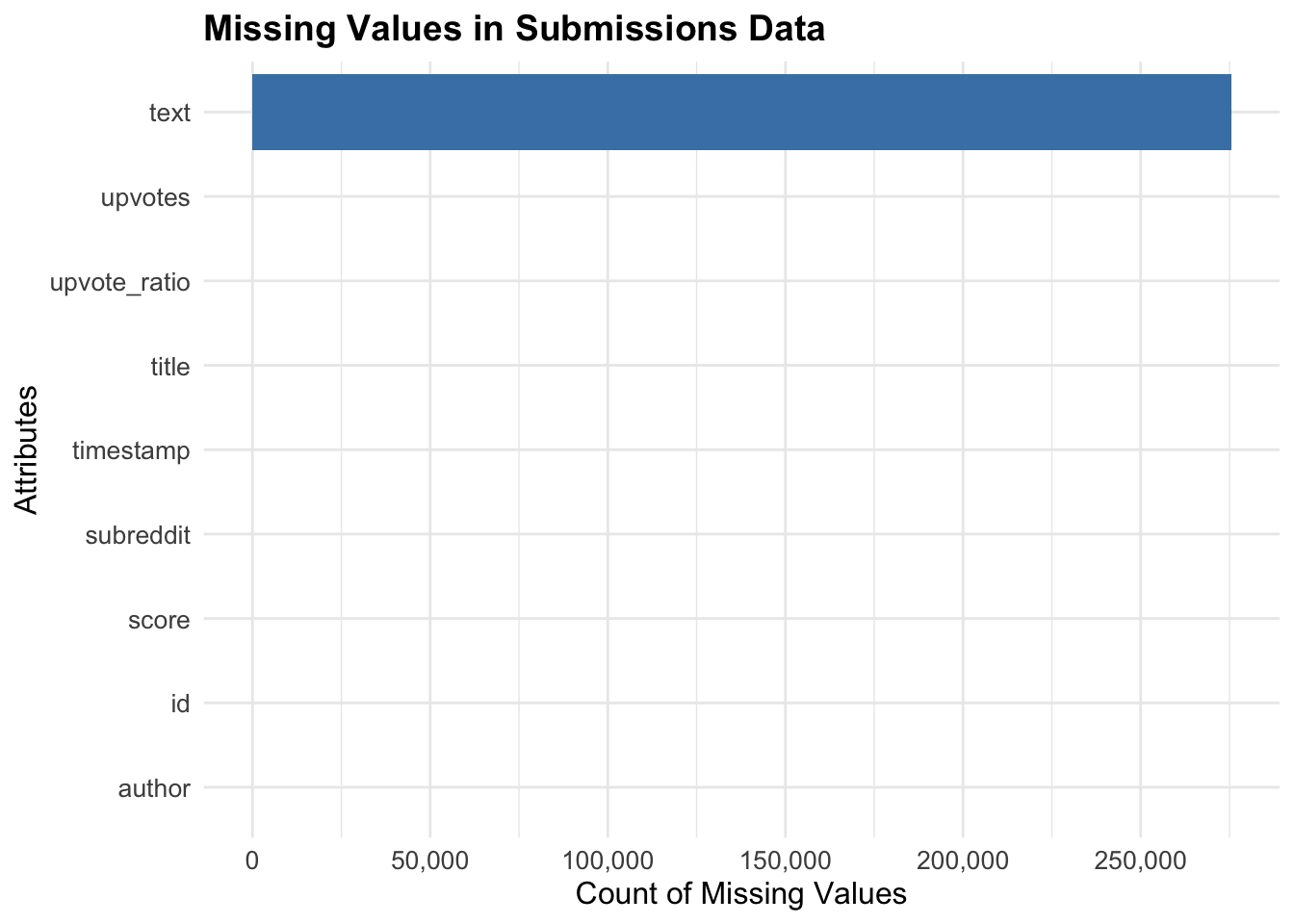
The text field has the highest count of missing values, surpassing 250,000. This is expected since many submissions on Reddit consist only of a title without any additional text in the body. The absence of text in a large number of submissions does not hinder the analysis significantly, as the title typically captures the key content of Reddit posts. All other attributes—such as upvotes, upvote_ratio, title, timestamp, subreddit, score, id, and author—have no missing values. This suggests that the dataset is complete for these attributes, which will ensure that our analysis for future engagement metrics and temporal trends are accurate.
Code
missing_values_comments <- comments %>%summarise(across(everything(), ~sum(is.na(.)))) %>%pivot_longer(cols =everything(), names_to ="attribute", values_to ="missing_count")ggplot(missing_values_comments, aes(x =reorder(attribute, missing_count), y = missing_count)) +geom_bar(stat ="identity", fill ="seagreen") +coord_flip() +labs(title ="Missing Values in Comments Data",x ="Attributes",y ="Count of Missing Values" ) +theme_minimal()
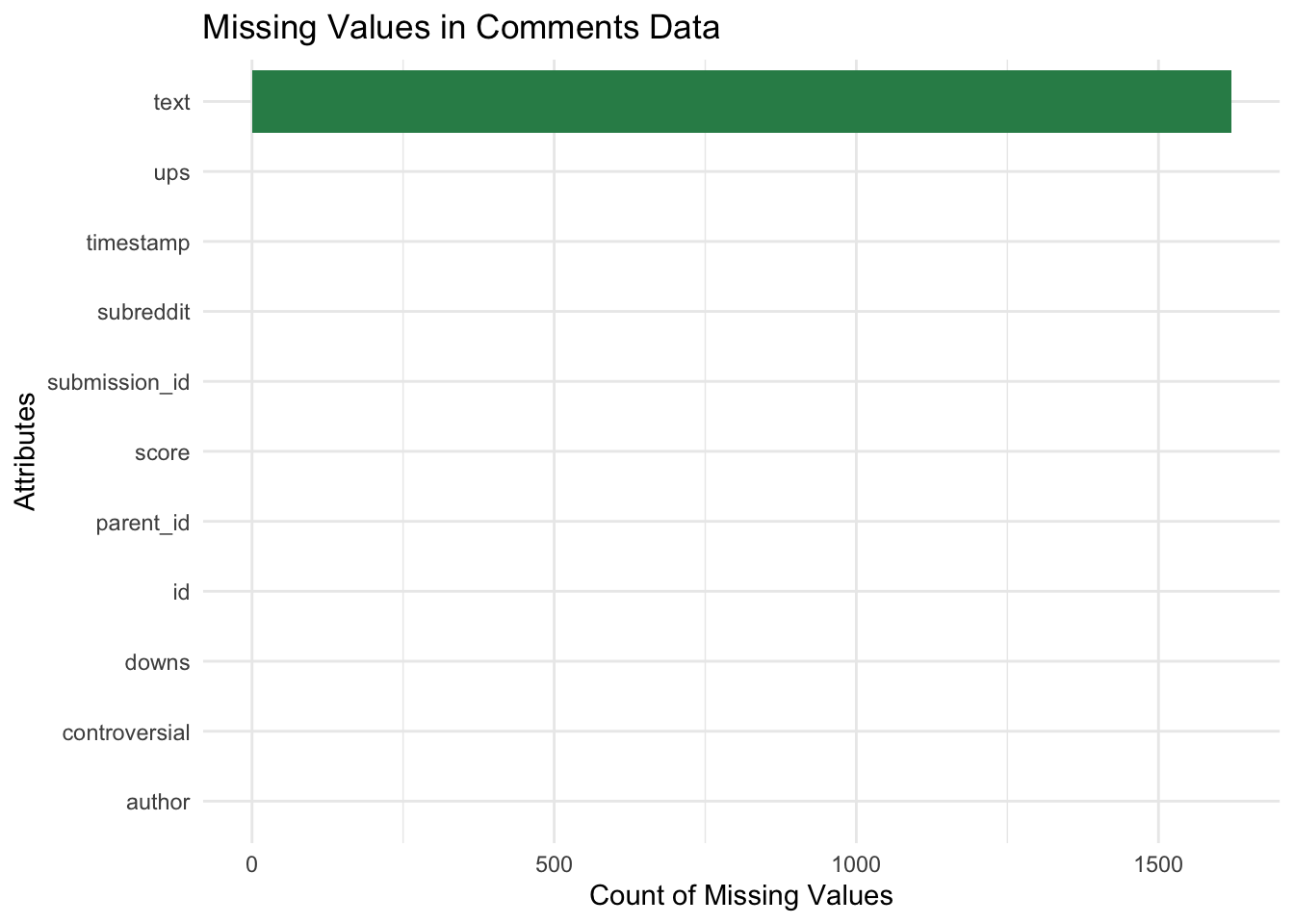
The text field in the comments data has the highest number of missing values, approximately 1,500. This is expected, as some comments might not have meaningful text content (e.g., deleted or removed comments by moderators or users). This is a common occurrence on Reddit and does not significantly impact overall analysis.
All other attributes, such as ups, timestamp, subreddit, submission_id, score, parent_id, id, downs, controversial, and author, show no missing values.
We wanted to analyse any missing values in the dataset to check the quality and reliability of our analysis using the dataset. For this project, we assessed the missing values in the submissions and comments datasets to identify any patterns and evaluate their impact on the analysis.
The submissions dataset contained a significant number of missing values in the text field, with over 250,000 entries lacking supplemental text for titles. This is not unexpected, as many Reddit posts only include a title without additional body text. However, all other key attributes—such as subreddit, id, author, timestamp, title, score, upvote_ratio, and upvotes—were complete, ensuring that the engagement metrics and temporal trends we wanted to focus on could be analyzed without issues.
In the comments dataset, the text field also exhibited missing values, with approximately 1,500 entries affected. This is likely due to deleted or removed comments, which is common on Reddit. Attributes such as ups, downs, score, timestamp, subreddit, and author were fully populated, ensuring that engagement trends and user activity could be analyzed. This did not significantly hinder our analysis in this project as we were focused on exploratory data analysis instead of modelling for sentiment and content analysis.